

Introduction à Apache Iceberg
Apache Iceberg est un format de table open-source conçu pour les ensembles de données analytiques massifs, offrant un moyen fiable de gérer les données dans un data lake comme s’il s’agissait d’une base de données traditionnelle. Initialement développé chez Netflix pour surmonter les limitations des anciens formats de table Hadoop (comme Apache Hive), Iceberg a ensuite été donné à la Fondation Apache Software. Son objectif est d’apporter des fonctionnalités similaires à celles des bases de données – telles que les transactions ACID, l’évolution du schéma, la flexibilité des partitions et les requêtes de voyage dans le temps – aux data lakes de l’échelle du pétaoctet. En substance, Iceberg définit comment les métadonnées sont stockées et comment les fichiers de données sont organisés dans une table, sans remplacer le format de stockage sous-jacent (il fonctionne avec Parquet, ORC, Avro, etc.). Ce design agnostique vis-à-vis de la technologie permet à Iceberg d’être utilisé avec divers moteurs de traitement (Spark, Hive, Impala, Flink, etc.) et sur différents systèmes de stockage (HDFS, stockages d’objets cloud), tout en garantissant une sémantique de table cohérente sur toutes les plateformes.

Fonctionnalités clés et différenciation : Plusieurs fonctionnalités clés distinguent Iceberg des approches antérieures et des autres formats de table :
- ACID et Écritures Concurrentes : Les tables Iceberg prennent en charge les transactions ACID avec un isolement par instantané (snapshot isolation), permettant à plusieurs utilisateurs ou moteurs de lire et d’écrire simultanément sans corrompre les données. C’est une amélioration significative par rapport aux lacs de données de style Hive, qui manquaient de commits atomiques et souffraient souvent de problèmes de cohérence lors d’écritures concurrentes.
- Évolution du Schéma et des Partitions : Iceberg permet l’évolution du schéma en place (ajout, suppression ou renommage de colonnes) et l’évolution des partitions sans réécritures coûteuses. Contrairement aux partitions statiques de Hive, Iceberg permet de mettre à jour les stratégies de partitionnement à mesure que les données augmentent ou que les modèles de requête changent, tout en continuant à interroger de manière transparente les anciennes données.
- Partitionnement Caché : Iceberg introduit le partitionnement caché, éliminant le besoin d’ajouter des clés de partition artificielles en tant que colonnes. Les métadonnées de partition sont stockées dans Iceberg, permettant aux moteurs de requête de pruner automatiquement les données en fonction des valeurs réelles (par exemple, la date ou le hash) sans nécessiter de suggestions de requête de la part de l’utilisateur. Cela simplifie considérablement la conception des tables pour les architectes de données.
- Voyage dans le Temps et Restauration de Version : Chaque changement crée un nouvel instantané (snapshot). Les utilisateurs peuvent interroger les données à un instantané spécifique ou à un moment donné (requêtes de voyage dans le temps) et même revenir à des versions antérieures de la table si nécessaire. Cela est inestimable pour le débogage, les audits ou la recherche reproductible (par exemple, relancer un rapport sur les données de la semaine dernière).
- Compatibilité Multi-Moteurs, Vue Cohérente : Iceberg offre une spécification ouverte et une bibliothèque qui permettent à n’importe quel moteur de calcul de l’utiliser. Des moteurs comme Hive, Impala, Spark, Trino, Flink et d’autres peuvent lire et écrire sur la même table Iceberg tout en voyant les mêmes données et schémas. Cela contraste avec les formats propriétaires liés à une seule plateforme. L’adoption massive d’Iceberg (par Cloudera, Snowflake, Netflix, Apple, AWS, et d’autres) témoigne de sa neutralité et de sa flexibilité dans les architectures de données modernes.
En répondant à ces besoins, Apache Iceberg est devenu un élément clé de l’architecture Lakehouse – combinant l’évolutivité et la flexibilité des data lakes avec la fiabilité et la structure des data warehouses. Dans les sections suivantes, nous explorerons l’architecture technique d’Iceberg et son intégration dans un Lakehouse, avec des exemples pratiques dans l’écosystème de Cloudera.
Fonctionnement d’Apache Iceberg
L’architecture d’Apache Iceberg repose sur une approche en couches pour les métadonnées qui suit l’état des tables et les fichiers de données de manière efficace. Contrairement à Hive qui utilisait le listing des répertoires ou un metastore central pour suivre les fichiers, Iceberg stocke les métadonnées dans une série de fichiers (souvent dans le même stockage que les données), agissant comme le plan de contrôle de la table. Cette conception garantit que la lecture ou l’écriture dans une table Iceberg ne nécessite que quelques consultations de métadonnées en temps constant, indépendamment de la taille de la table (évite les opérations coûteuses qui augmentent avec le nombre de fichiers ou de partitions). Les principaux composants de l’architecture des tables Iceberg sont :
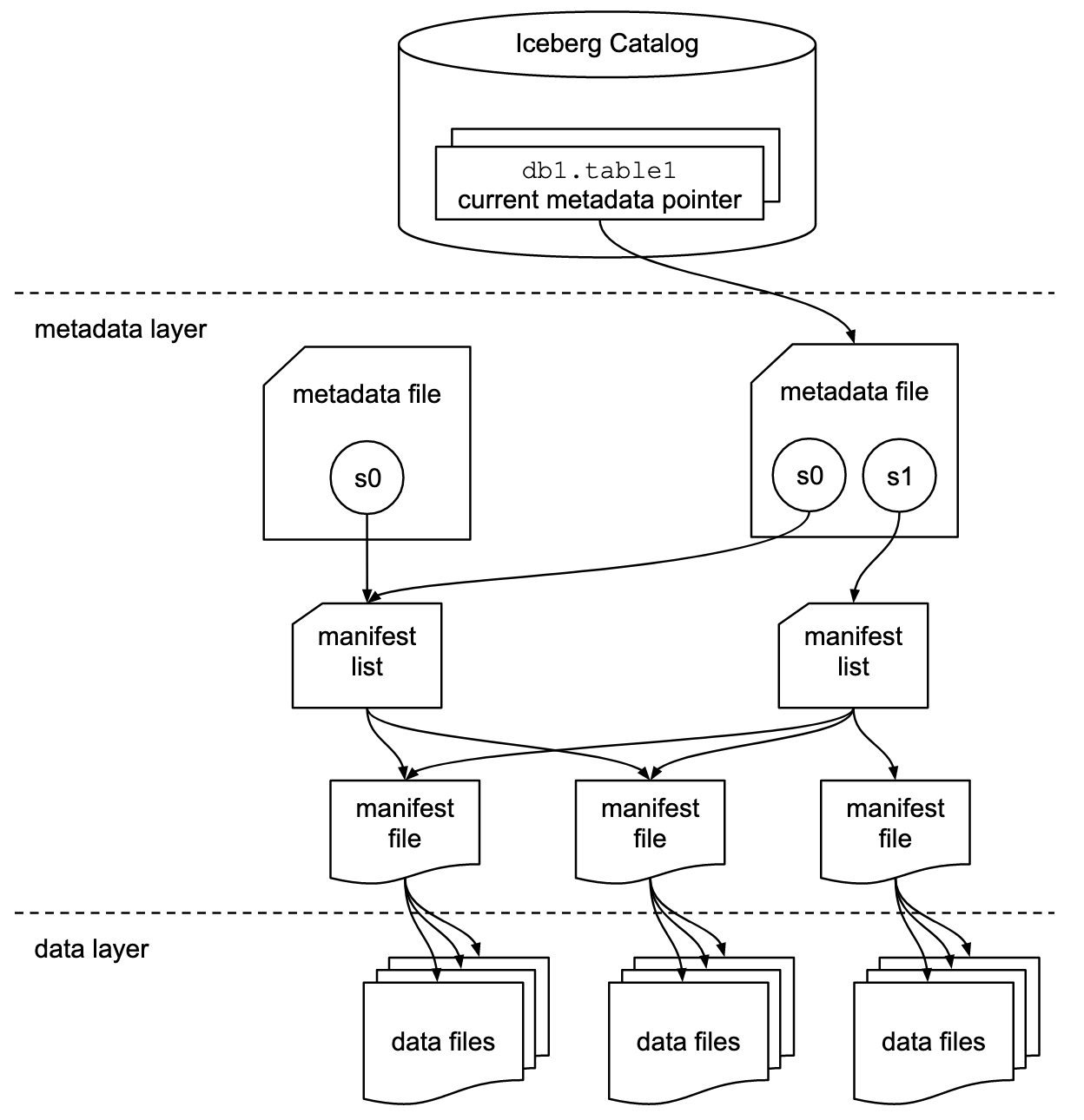
- Catalogue (Catalog) : Le catalogue garde une trace de toutes les tables Iceberg et sert de point d’entrée pour les moteurs de traitement. Il stocke l’emplacement du fichier de métadonnées actuel de chaque table. Dans Cloudera, par exemple, le Hive Metastore peut jouer le rôle de catalogue Iceberg, en stockant un pointeur vers les dernières métadonnées de la table ainsi que quelques informations de haut niveau.
- Table Metadata File : Un fichier de métadonnées contient le schéma de la table, la spécification des partitions et une liste de tous les instantanés de la table. Chaque fois qu’une table est mise à jour (insertion, mise à jour, suppression ou changement de schéma), un nouveau fichier de métadonnées est écrit, faisant référence aux métadonnées précédentes et à l’instantané le plus récent. Ce fichier joue un rôle de gestion des versions de la table – permettant des retours en arrière et le suivi de l’historique du schéma. Le fichier de métadonnées liste également d’autres fichiers de métadonnées (comme les manifests) qui composent l’instantané le plus récent.
- Snapshots and Manifest Lists : Un (snapshot) représente l’état de la table à un moment donné. Techniquement, un instantané est codé sous la forme d’un fichier manifest list, qui est une liste de pointeurs vers tous les fichiers manifests qui composent cet instantané. La liste de manifests inclut des métadonnées sur chaque manifest (par exemple, les partitions couvertes, le nombre de fichiers), permettant au moteur de requête de décider rapidement quels manifests (et donc quels fichiers de données) sont pertinents pour une requête donnée. Chaque instantané est immuable ; de nouveaux instantanés sont créés à chaque changement de table, permettant des requêtes de voyage dans le temps en sélectionnant un instantané spécifique.
- Fichiers Manifests (Manifest Files) : Un manifest est un index détaillé d’un sous-ensemble des fichiers de données de la table. Chaque fichier manifest contient une liste d’entrées de fichiers de données ainsi que des métadonnées telles que les valeurs de partition et les statistiques de colonnes (par exemple, les valeurs min/max pour chaque colonne dans ce fichier). Les manifests sont essentiels aux performances de requête d’Iceberg. Ils permettent aux moteurs de requête de pruner rapidement des ensembles entiers de fichiers : par exemple, si une requête filtre par date, Iceberg ne lira que les manifests et fichiers de données pertinents pour les partitions de date concernées, en ignorant les autres. Comme les manifests eux-mêmes sont suivis dans la liste des manifests, Iceberg peut réutiliser des manifests entre les instantanés si les fichiers de données n’ont pas changé, évitant ainsi de réécrire les métadonnées pour chaque nouvel instantané.
- Fichiers de Données (Data Files) : Ce sont les fichiers de stockage réels (par exemple, Parquet, ORC, Avro) contenant les lignes de la table. Iceberg ne prescrit pas de format de fichier spécifique ; il fonctionne sur des formats de fichiers colonnes pris en charge par les moteurs de traitement. Les fichiers de données sont organisés dans le répertoire de stockage de la table mais ne sont pas exposés directement aux utilisateurs – les métadonnées d’Iceberg indiquent aux moteurs de traitement quels fichiers de données lire pour une requête donnée. Lorsque de nouvelles données sont écrites, de nouveaux fichiers de données sont créés et ajoutés à un nouvel instantané ; lorsque des données sont supprimées ou mises à jour, Iceberg crée des fichiers de suppression (delete files) ou omet simplement ces fichiers de données dans un nouvel instantané (dans les tables V2, les manifests de suppression peuvent suivre les suppressions au niveau des lignes).
Isolation Serializable et Commits Atomiques : Toutes les écritures dans Iceberg suivent un modèle de concurrence optimiste avec commits atomiques. Les auteurs de requêtes préparent de nouvelles métadonnées d’instantané et tentent de remplacer de manière atomique le pointeur des métadonnées actuelles de la table par le nouveau. Si un autre processus a mis à jour la table entre-temps, le commit échoue et est généralement réessayé en utilisant les nouvelles métadonnées les plus récentes (cela évite les conflits). Cette conception garantit que les lecteurs ne voient jamais d’écritures partielles – une table passe d’un instantané cohérent à l’autre, ou pas du tout.
Efficacité à grande échelle : Grâce à sa hiérarchie de métadonnées, la planification des requêtes dans Iceberg est extrêmement efficace pour les grandes tables. Elle évite les opérations coûteuses de listing de répertoires d’Hive en maintenant un index des fichiers dans les manifests. La planification d’une requête implique la lecture d’un petit fichier de métadonnées et de quelques manifests, plutôt que de parcourir une immense structure de répertoires. La spécification Iceberg met l’accent sur des consultations de métadonnées en O(1) : que la table ait 10 partitions ou 10 000, le coût d’ouverture de la table reste quasi constant. Cela permet de gérer élégamment même des tables de plusieurs pétaoctets avec des millions de fichiers.
Apache Iceberg dans une Architecture Lakehouse
L’architecture data lakehouse est une approche moderne qui combine les éléments des data lakes et des data warehouses. Dans un lakehouse, les données sont stockées dans un stockage à faible coût (comme un data lake), tout en imposant une structure de table et des garanties transactionnelles (comme un data warehouse), permettant une large gamme d’analyses directement sur les données du lac. Apache Iceberg joue un rôle central dans cette architecture en fournissant le format de table ouvert qui agit comme le « ciment » entre le stockage et les moteurs de calcul.
Support Multi-Moteurs :
Un des piliers du lakehouse est la capacité de permettre à divers moteurs analytiques et charges de travail de fonctionner sur les mêmes données. Iceberg a été conçu avec cette idée en tête – il n’est pas lié à un moteur d’exécution spécifique. Que vous exécutiez des requêtes SQL avec Apache Impala, des analyses interactives avec Hive, des traitements en streaming avec Flink, ou des pipelines de machine learning avec Spark, chaque moteur peut lire et écrire sur les mêmes tables Iceberg de manière fiable. Cela résout un défi majeur des data lakes précédents, où il était difficile de maintenir la cohérence des schémas et des données entre les différents outils. Grâce à l’abstraction des tables Iceberg, tous les moteurs voient une vue cohérente des données et du schéma, et les modifications apportées par un moteur (par exemple, un job Spark ETL) sont immédiatement visibles par les autres (par exemple, une requête de tableau de bord Impala) une fois validées.
Stockage Ouvert et Séparation du Calcul :
Les architectures lakehouse mettent l’accent sur le stockage des données dans des formats ouverts sur un stockage central accessible à tous (souvent des stockages d’objets cloud ou HDFS) et sur l’évolutivité indépendante des moteurs de calcul. Iceberg s’intègre parfaitement ici en séparant la définition des tables de tout cadre de traitement spécifique. Les données et les métadonnées résident dans la couche de stockage (fichiers dans un stockage objet ou HDFS), et n’importe quel moteur qui comprend la spécification d’Iceberg peut les interroger. Cela signifie que vous n’êtes pas lié à un fournisseur de stockage ou à un format propriétaire – un facteur crucial pour les architectes de données qui recherchent une longévité et une flexibilité dans leur plateforme de données. Par exemple, si toutes vos données sont sur S3 ou HDFS, vous pouvez les interroger avec Spark aujourd’hui et passer à Trino ou Dremio demain avec un minimum de friction, grâce aux standards ouverts d’Iceberg.
Avantages par rapport aux Data Lakes traditionnels :
Comparé à un data lake Hadoop traditionnel (par exemple, des tables Hive sur HDFS), un lakehouse basé sur Iceberg apporte de nombreuses améliorations :
- Mises à Jour Fiables des Données : Dans les anciens data lakes, la mise à jour ou la suppression de données était fastidieuse (souvent en réécrivant des partitions entières ou en utilisant Hive ACID qui était lourd). Iceberg permet des INSERT, UPDATE, DELETE directs avec des garanties ACID, rendant la mutation des données gérable sur le lac.
- Unification du Batch et du Streaming : Un lakehouse doit prendre en charge à la fois l’analyse par lots et les données en temps réel. Les tables Iceberg peuvent être mises à jour de manière incrémentale par des pipelines de streaming (par exemple, en utilisant Flink ou Spark Structured Streaming) tout en étant simultanément interrogées par des jobs batch. L’isolement par instantané garantit que les écritures en streaming n’interrompent pas les requêtes en cours.
- Scalabilité des Métadonnées : Les data lakes basés sur Hive Metastore ont souvent du mal à gérer des millions de partitions ou de fichiers (le problème bien connu de la scalabilité du metastore). La conception d’Iceberg déplace le suivi des partitions dans les métadonnées des fichiers, réduisant considérablement la charge sur le metastore central et permettant aux tables avec des dizaines de milliers de partitions de fonctionner sans problème.
- Auditabilité et Voyage dans le Temps : Chaque changement dans Iceberg crée un nouvel instantané, offrant ainsi un journal des modifications des données. Les analystes ou les responsables de la conformité peuvent interroger les données à une date passée ou même revenir à un état antérieur de la table si nécessaire. Cette fonctionnalité intégrée de voyage dans le temps (time travel) prend en charge la reproductibilité dans les analyses et les cas d’utilisation scientifiques (par exemple, relancer un rapport sur des données historiques pour comparer les tendances).
En résumé, Iceberg apporte les fonctionnalités du « warehouse » au « lake ». Cloudera qualifie Iceberg de « sauce secrète du lakehouse ouvert » car il permet une plateforme unifiée où les données structurées et non structurées peuvent coexister et être interrogées avec des performances élevées. Pour les architectes de données, choisir une architecture lakehouse basée sur Iceberg permet d’éviter le verrouillage propriétaire tout en répondant aux exigences d’entreprise en matière d’intégrité des données.
À lire aussi : Apache Iceberg dans Cloudera Private Cloud Base Edition Lire l’article ici
Mehdi TAZI – CTO & Data Architect a BI-NEWVISION